23장 길찾기
제 23장 길찾기
기본적인 길찾기
무작정 튀기기
벽 짚고 따라가기
견고한 길찾기 방법들
너비 우선 탐색
좀 더 똑똑한 길찾기
A* 길찾기
그래픽 데모 : 경로 비교
가중치가 부여된 맵
응용 : 잠입
타일맵이 아닌 맵에서의 길찾기
선 기반 길찾기
4진 트리
웨이포인트
결론
학습 내용
너비 우선 탐색을 이용한 길찾기
너비 우선 탐색 길찾기의 개선
휴리스틱을 이용한 길찾기의 개선
더 나은 휴리스틱을 만들려면?
A* 길찾기의 작동 방식
가중치 맵의 활용
비 타일 기반 길찾기
기본적인 길찾기
무작정 튀기기

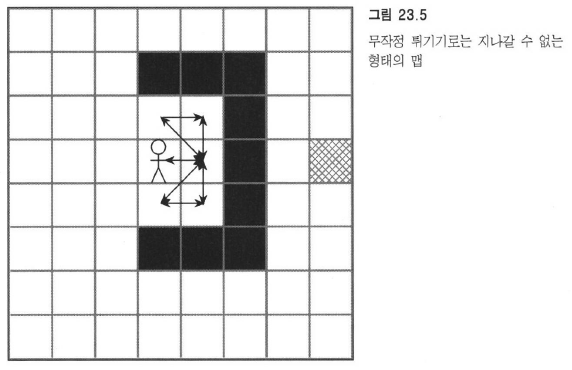
멍청하다.
벽 짚고 따라가기


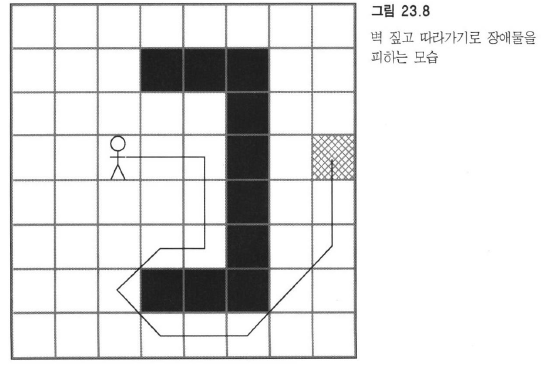
위에보단 낫지만 여전히 멍청해보인다.
이렇게 미래를 바라보지 않고 눈 앞의 상황만을 근거해서 길을 찾는 걸 ‘즉자적인’ 길찾기라고 하는데, 좀 더 지능적으로 도달할 때의 경로가 최대한 짧게 끔 신경쓰는 문제를 최단경로 (shortest path) 문제라고 한다.
견고한 길찾기 방법들
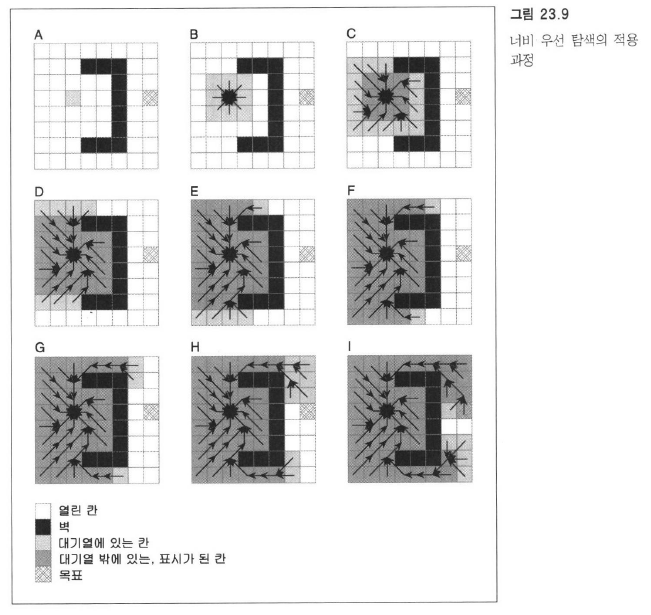
너비 우선 탐색
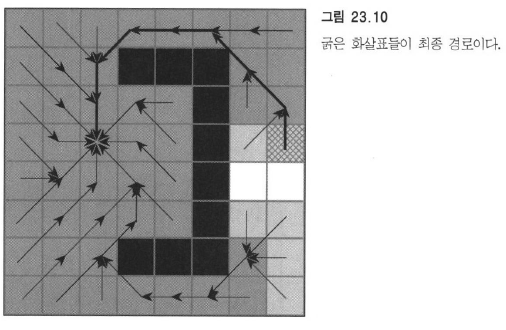
그래프에서 이미 맛본 BFS는 한 칸 거리에 있는 칸부터 모두 처리하고 다음 칸으로 넘어가는 방식이다.
너비 우선 탐색은 큐를 사용한다. 각 칸은 ‘이전 노드 정보’를 가지고 있어서 목표에 도달했을 때 하나의 경로를 만들어낸다.

BFS 길찾기의 개선
위의 너비 우선 탐색은, 수직/수평 거리와 대각선 거리를 같다고 처리하는데 실제로는 대각선의 길이가 더 길다.
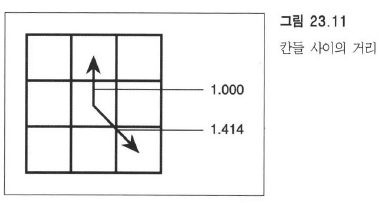
이걸 개선하려면 어떻게 해야 할까.
방문 순서의 수정
기존엔 순서가 그냥 시계방향으로 되어있기 때문에, 3의 바로 옆 칸을 간다고 했을 때 2가 먼저 처리되어 대각선이 더 빠른걸로 나오게 된다. 일단 순서를 다음과 같이 바꿈으로서 개선해볼 수있다.


그러나 칸 수가 많아지면 이것도 근본적인 해결책이 되지는 못한다.
진정한 너비 우선 탐색
문제의 근본적인 원인은 인접한 칸들이 같은 거리에 있다는 점이다. 즉 탐색 공간이 정사각형이다.

위그림에서 일반적인 너비 우선 탐색이라면 기준점에서 (0, 0)의 거리와 기준점에서 (2,0)의 거리가 같다는 문제가 있다.
실제로는 왼쪽 그림같이 0.8의 차이가 있다. 따라서 너비 우선을 오른쪽의 거리 우선처럼 개선할 수 있다.

직선상의 거리라면 거리 우선 탐색이 원형이므로 탐색할 노드 수가 적어 더 효율적이다 (21퍼센트 정도)
그러나 대각선 거리라면 너비 우선 탐색이 유리하다 (36퍼센트 정도)
이렇게 최악의 경우만 놓고 보면 일반적인 너비 우선이 좋아보이지만, 일반적인 너비 우선 방식으로는 가중치가 부여된 맵을 처리할 수 없다.
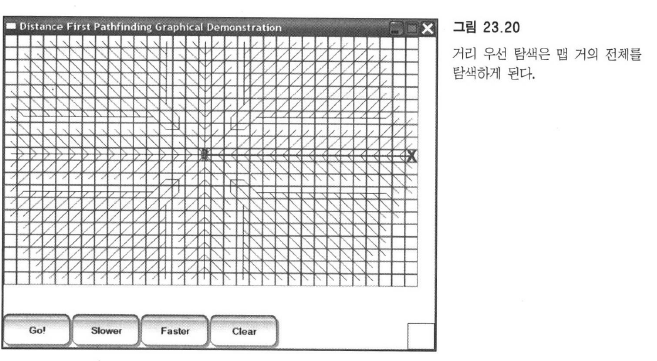
그래픽 데모 : 거리 우선 길찾기
거리 우선 길찾기의 구현
기반 코드
Cell 클래스
Coordinate 클래스
칸들의 초기화
거리 함수
상수들
enum DIRECTION //현재까지의 거리 + 인접타일의 가중치 * 방향별 거리(대각선이면 1.4) |
위는 책의 코드. 불필요한 코드 반복이 있어서 좀 축약하고 변수이름을 서술적으로 바꿨다.
나중에는 내 스타일대로 만들어보자.
좀 더 똑똑한 길찾기
하지만 이걸로는 만족할 수 없다. 현재 방식으로는 다음과 같이 모든 방향을 다 검색하기 때문이다.
위의 코드(거리 우선 탐색)에서는 인접한 칸들을 그냥 순서대로 선택할 뿐이다.
휴리스틱(발견적 값)을 적용시킴으로써 어떤 칸을 선택해야할지 정할 수 있게 해야한다.
즉 목표에 보다 가까운 칸들이 먼저 처리되도록 해야 한다.
그렇다면 어떤 기준으로 칸을 처리할 것인가?
우선 각 칸의 휴리스틱 값이 현재 타일에 비해 목표와 얼마나 가까운지를 나타내게끔 해볼 수 있다.
다음 그림을 보자.

북쪽 칸은 현재 타일에 비해 y가 1 가까워졌으므로 -1, 북동 칸은 x와 y가 모두 가까워졌으므로 -2다.
다른 타일들도 같은 방법으로 처리한다. 우선순위큐에는 휴리스틱 값이 낮은 순으로 저장될 것이므로
다음 번 반복에서는 북동쪽 칸이 처리될 것이다.
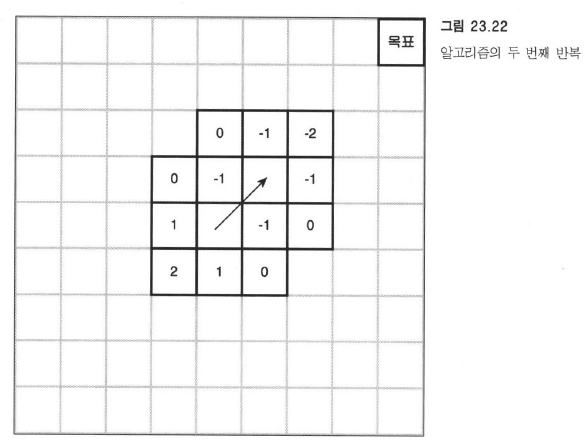
매우 간단한 휴리스틱 알고리즘이지만, 탐색의 효율이 크게 증가했다는걸 알 수 있다.
이 길찾기 방법의 문제
가중치를 고려하지 않으므로 발견된 최단 경로가 아닐 수 있다.
목표를 향한 방향만을 생각하기때문에, 가중치가 없는 경우에도 최단 경로가 아닐 수 있다.
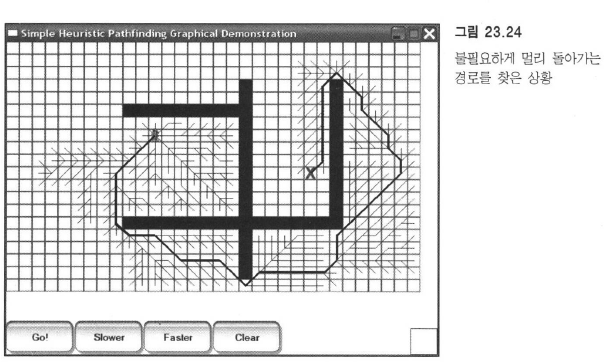
목표가 출발점보다 낮기 때문에 밑을 더 우선시하다보니 멀리 돌아간다.
경로 자체는 비효율적이지만 탐색한 공간이 크지 않고 전반적인 검색 시간도 길지 않아서
좀 더 (성능적으로)빠르게 길을 찾아야할 때 유용하다.
간단한 발견적 길찾기의 구현
이 방법을 구현하는 건 이전에 만든 거리 우선 길찾기와 비슷하다.
float SimpleHeuristic(int curX, int curY, int goalX, int goalY, int dir) |
책의 코드를 좀 더 축약했다.
이제 이전 코드의 newCoord.heuristic = distToAdj; 를
newCoord.heuristic = SimpleHeuristic(curX, curY, goalX, goalY, distToAdj);
로 바꿔주기만 하면 끝!
길 찾기 알고리즘은 처음 배우는데 이 부분의 단순함은 정말 놀랍다.
힙의 놀라운 장점인걸까?
발견적 방법의 개선
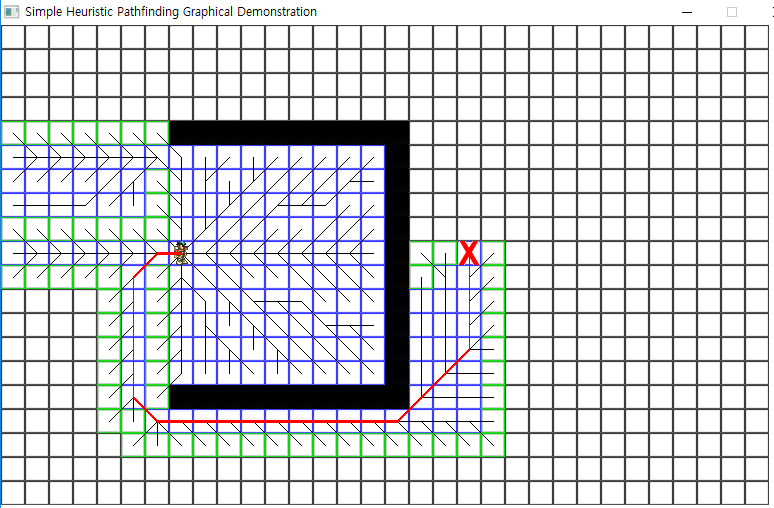
이 단순한 휴리스틱의 또다른 단점은 목표와 y가 같을 때에 있다.
알고리즘으로서는 목표와 같은 y를 벗어나는게 비싼 행동이므로 먼저 x를 모두 살펴보기 때문이다.
이 단순한 휴리스틱은 각 탐색에서 주어진 칸이 이전 칸에 비해 좀 더 가깝냐 멀어지냐를 따진다.
상대적인 거리를 이용하는 것인데, 이를 절대 거리로 바꾸어보자.

이렇게 하면 실제로 더 가까울수록 우선순위가 올라간다.
이 방법의 문제점
이 방법도 첫 번째의 누운 4 테스트에서 멀리 돌아간다.
무조건 “자기 자신과 목표까지의 거리”에만 신경쓰기 때문이다.”
즉 어떤 한 지점에서 목표보다 먼 쪽을 선택하는게 더 짧을 수 있는 경우를 무시하는 것이다.
또한 현재는 가중치를 고려하지 않고있다.
복잡한 발견적 방법의 구현
새 발견적 함수
float ComplexHeuristic(int curX, int curY, int goalX, int goalY, int dir) |
간단!
A* 길찾기
그렇다면 그 유명한 에이스타는 대체 뭘까?
A*에는 우리가 이전에 살펴본 단점이 없다. ‘최단’경로인 셈이다.
이전의 두 방법의 문제는 현재까지의 경로 길이를 생각하지 않고 휴리스틱 값만 생각한다는 것에 있다.
즉 제대로된 경로를 얻을려면 현재 경로의 길이도 휴리스틱 값으로 사용해야 한다는 것.

위 그림이 A*의 전부다. 전체 비용 = 어떤 칸 까지의 비용 + 목표까지의 비용.
위의 칸은 6.53의 비용이, 밑의 칸은 8.32의 비용이 든다.
A* 길찾기의 구현
A* 길찾기 함수는 이전 세 길찾기 함수와 거의 비슷하다!
c.heuristic = ComplexHeuristic (curX, curY, goalX, goalY, dir) + distance
이것이 전부! 놀랍다!
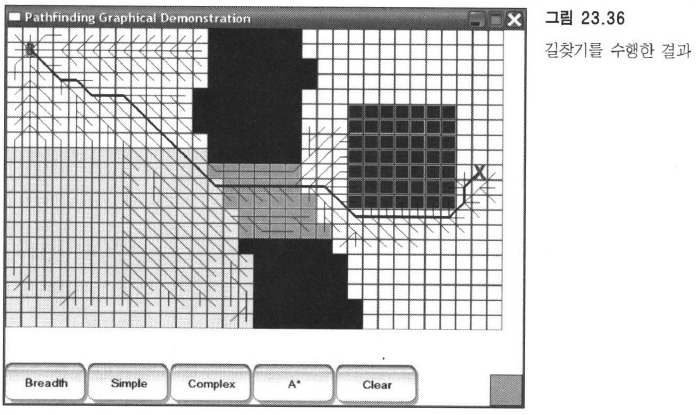
그래픽 데모 : 경로 비교

거리우선 탐색과 a*의 최단거리는 같지만 거리우선은 훨씬 더 많은 노드를 탐색했다.
가중치가 부여된 맵
맵의 특정 타일들에 속성을 줘서 지나가기 어렵게 해보자.

응용 : 잠입
최단경로를 사용할 때는 목표에서부터 역으로 추적하면서 좌표를 스택에 담으면 된다.
맨 위는 시작점이니까 빼주자.
타일맵이 아닌 맵에서의 길찾기
선 기반 길찾기
4진 트리
웨이포인트
결론
길 찾기라는 주제의 방대함에서 이 챕터의 내용은 아주 작은 것일 뿐이다.
게임 프로그래밍에서 잊지 말아야할 것은 언제나 더 나은 방법이 존재한다는 사실이다.
이번 장을 통해서 여러 길찾기 알고리즘들과 아이디어들, 그리고 막무가내식 알고리즘과 똑똑한 알고리즘을 구분하는 능력이 생겼길!
'프로그래밍 책 공부' 카테고리의 다른 글
| 2장 템플릿 (0) | 2018.03.24 |
|---|---|
| 게임 프로그래머를 위한 자료구조와 알고리즘 - 목차 (0) | 2018.03.23 |
| 1. 디자인 패턴 소개 (0) | 2018.03.19 |
| 목차와 서문 (0) | 2018.03.19 |